



Reviewing the review: A critical look at the Vals Legal AI Report
A look under the hood of a domain-specific benchmark study designed to evaluate leading legal AI tools and how they measure up against human lawyers.

In the past week the Vals Legal AI Report (VLAIR) garnered a good amount of attention amongst tech-affine lawyers. LinkedIn was no exception and immediately mostly general views on AI were exchanged along familiar lines: Those who see legal AI as charlatanry, and those who profess the end of the profession to be nigh.
First things first: VLAIR represents a much needed initiative to dispassionately assess the performance of 'leading legal AI tools' across various tasks, moving beyond promotional narratives with the goal to provide empirical insights. While benchmarks are not always seen entirely in a positive light, and other legal benchmarks like LawBench or LegalBench have existed for some time - though with a different focus - independent evaluations are essential for legal professionals seeking to understand the practical utility of legal AI tools and have been hard to come by.
VLAIR’s results are interesting, but looking at the report in detail also left me with a great number of questions as to the evaluation design, which unfortunately then cast some doubt onto the robustness of its findings.
The authors present VLAIR as a
“first-of-its-kind study [that] evaluates how four legal AI tools perform across seven legal tasks, benchmarking their results against those produced by a lawyer control group”.
This remit invites the question: Will the benchmark’s results be as insightful, as it appears on a first pass? By asking who performs better, the setup carries a flavour of a ‘face-off between human lawyers and legal AI tools’. On the other hand, except for the hype/influencer type, few people actually expect that the class of tools under review here will soon replace lawyers (or professionals in any other domain really). The more plausible near term future is not having one's job replaced by AI, but ‘having it replaced by someone using AI'. Therefore, rather than comparing performance levels of humans and AI tools, the more actionable insight - for lawyers and also makers of the tools - might have been to assess how well these legal tools augment the delivery of legal services. The authors acknowledge this to a degree when they conclude that
"in their current state, the output of generative AI tools should be viewed as a starting point for further work by the lawyer"
but somehow the benchmark does not seem to evaluate this dimension of the tools' usefulness. I have included a few comments throughout to illustrate this point.
In next few pages I’ll briefly cover the results, the evaluations's scope and then review some potential criticism in the benchmark design and its room for improvement in future rounds.
A. Results
Based on the report at least one of the AI tools outperformed human lawyers in all but 2 of the evaluated tasks (redlining - i.e. analysing and drafting contract revisions - and EDGAR research) and were on par with the human baseline on one other task (chronology generation). Harvey Assistant was leading the pack receiving top scores in 5 of the 6 tasks in which it was evaluated. ThompsonReuter's CoCounsel is the only other AI tool that received a top score.

These results appear impressive on first sight, thought there are a few details I would urge to take into account before drawing conclusions from these figures, and I have laid out my arguments below.
B. VLAIR Scope
The report evaluated four legal AI tools, across seven distinct tasks that many lawyers would have come across in their practice. The coverage of the evaluation is unfortunately more limited, because not every product was evaluated on all 7 tasks, and some vendors withdrew their participation from certain tasks (marked with a ↩️).

In addition, LexisNexis' Lexis+AI was initially part of the evaluation, but withdrew altogether before the report was published. It would be difficult to know with certainty, but it’s hard to come up with a plausible explanation for this decision other than LexisNexis being unhappy with the performance of their product - though the report does not give any indication as to this reason or any other. Considering TR's showcasing of CoCounsel as an advanced legal drafting tool and its leveraging of legal playbooks, I find it somewhat curious that CoCounsel was not put to the evaluation of its redlining capabilities, which the benchmark defines as
"relevant to the review and negotiation of a contract by doing one of three things:
1. Suggest an amendment to a provision or contract to bring it in line with a provided standard.
2. Identify whether certain terms in a provision or contract match a provided standard and, if not, suggest an amendment to bring it in line.
3. Review a redlined contract, identify the changes, and explain the impact of the changes and/or recommend steps to address the change."
Each of the 7 task categories was evaluated along the following number of questions, documents and correctness checks:

C. Observations
1. Evaluation opt-in and out
I found it interesting that all vendors were selective in participating in some, but not all of the 7 tasks. The answer might simply be that their tools are not made for all of the 7 tasks that VLAIR evaluated. On the one hand this seems fair, because not every tool can be made for every conceivable task, just like every lawyer knows that they cannot be an expert in every single aspect of the law.
On the other hand I believe it is reasonable to wonder why 50% of the vendors didn't want their tool - mind you specifically designed for the legal industry - to be evaluated for its abilities in the redlining (or drafting/reviewing) category of the benchmark, whereas all vendors were happy to have their tools evaluated on the 'much more general' tasks of data extraction, Q&A and summarisation. This leaves a lingering question: How especially adapt are these tools really for the legal industry and how do they outperform general tools? Including at least one vanilla LLM could have shed light here, but more on this below under 3.
All this is especially curious, because LexisNexis' completly withdrew from the study, and Harvey Assistant's and VincetAI's partially withdrew. This suggests that the benchmark's authors granted vendors some intermediary step of assessing results prior to publication. As mentioned earlier, I find it hard to imagine rational and compelling reasons to withdraw from the benchmark, other than vendors' dissatisfaction with the black on white results of the assessment.
2. GenAI-specific shortcomings are not discussed
The key concern that I continue to have regarding GenAI applications in a legal setting is whether this is in fact a promising technology for this use-case. While this is not the right place to juxtapose the probabilistic nature of GenAI technology and the rather deterministic approach lawyers tend to take with the words they use, there are two key issues that have plagued GenAI solutions from day one: unreasonably confident and authoritative answers, even when they contain ludicrous mistakes and - the classic - confabulations (or hallucinations how they are typically referred to).
Neither of these critical error dimensions seems to have been explicitly and appropriately considered in the review and I believe this is a substantial oversight. Of course, an analysis arriving at the wrong answer is immediately disqualifying. But this is not the entire story. These AI tools are promoted in large part as productivity maximisers. In this light, however, it does matter whether a tool outputs a long text that is worded with authority, but subtly wrong and hence actually leads to extra work, rather than saving time, because a 1,000 word answer has to be reviewed with a fine-toothed comb. I'll discuss one example from the review under ‘5. Scoring’ to further illustrate this point.
3. No participation of a vanilla LLM
Potential customers of these tools would have benefited from including reference to more general systems, which are already quite capable in many regards. Of course, a general access to Claude or GPT 4x would come with privacy concerns in tow, but it nevertheless seems like a missed opportunity, because it could have illustrated - or not - how domain specific tools are much more adapt to legal concepts than more general models. This is especially the case, because the few examples the benchmark authors discuss in their publication don't seem to indicate a superior understanding of legal concepts:
"In this example, all respondents were asked to extract a clause or section that related to a Most Favored Nation (MFN) provision. The document did not contain any information about an MFN by that description exactly. It did have a sentence that would be categorized as an MFN clause: “access to its personnel no less favorable than what it provides any other customer.”
Lawyers got it right:

CoCounsel also got full marks:

I don't have the details of the question and answer pair, but want to call attention to one issue: While the relevant wording was correctly extracted, and as such CoCounsel 'answered the question', it is worth pointing out (looking only at the lawyer's response), that CoCounsel did not actually reference the relevant clause. I admit that this is potentially caused by the specific prompt, but one could argue that this - in context incomplete - answer shouldn't bear full marks. I say this only, because it is not a truly helpful response if one were to work with this tool, especially in a longer contract of many 10s or even hundreds of pages.
The rest of the pack - even though the authors remind us that
"this is a single, randomly selected example from a larger corpus and therefore should not be confused with the findings of the overall results"
seems to some iteration of word search and as such failed to identify the MFN clause:


Harvey Assistant produced a rather strange response:

I believe this example illustrates the benchmark could have attempted to bring to the foreground where precisely the unique advantage of these legal AI tools lay as compared to more general tools. From this example - again, which might not be representative - I am left wondering why not include at least one general model and see how it stacks up?
4. Questionable lawyer baseline
The idea of baselining the study with human lawyers convinces (though see my question on the 'direction' of the benchmark above). It appears to give the good reference point to the actual capability of the benchmarked tools. The VLAIR authors explain that the lawyers who constitute the human level baseline were unaware that they participated in a study. This is also great, as it implements the equivalent of the (almost) gold standard in the natural sciences, the 'blind study', where the participants do not know key details of the experiment. As a next step the authors could consider whether going all the way to the 'double blind study' could yield further improvements, i.e. a format where neither the human participant, nor the human reviewer - to the extent used - know relevant details.
Unfortunately, this is arguably where the good news about the human baseline design end. Some of the below views include a certain level of conjecture, but VLAIR could take these reservations into account and/or clarify them for a repeat study.
a) Independent lawyers from an Alternative Legal Services Provider
The first source of criticism is that VLAIR sourced 'average' independent lawyers via an 'alternative legal service provider' (ALSP). While it's generally hard to say what the ability of an 'average' lawyer would be, I need to get a little bit into the weeds of the legal industry to make this point: What you need to know is that ALSPs have emerged over the last decade or so as an alternative to traditional law firms. Their promise is mostly to provide cheaper service for more 'run of the mill'-kinds of tasks, that don't require very expensive experts. Some of these providers have been very successful with their offering and there is definitely a segment of the market and suitable work that makes ALSPs a great and cost-effective alternative to USD1,000 hourly rates of Wall Street or Magic Circle firms. With this is mind and even without extensive knowledge of the legal industry, one might surmise that lawyers working for ALSPs are generally not drawn from the top ranks of the legal profession, though - as always with generalisations - exceptions certainly do exist.
It is really hard to assess the quality of the participating lawyers, but I picked up on one detail that the review pointed to, which I believe allows a glimpse:
In the section covering Q&A VLAIR explains that
"AI tools demonstrated an ability to comprehensively capture nuanced details without experiencing cognitive fatigue. For example, in response to a question asking, “Can this contract be terminated for cause or breach?”, the lawyers correctly responded that the contract could be terminated for cause or breach, but failed to include that a cure period applied in certain circumstances—a caveat that all of the AI tools included in their response."
This leaves me with many questions around the instructions given to the participating lawyers, but more importantly how commercially minded these contractors were. This is because one of the first things young lawyers have to learn is that clients often don't actually know to ask the ’right questions’, but rather that clients have to be guided and that useful legal advice is always commercial. Therefore, simply answering the question whether the contract can be terminated for beach with a short "yes", while failing to point out - depending on the context and timeline of the facts - a relevant cure (which could change the practical answer to the exact opposite!) is either poor instruction to someone who is just trying to get through their day or indication of a less than desirable quality of a legal professional. If the latter were the case, then the human baseline is not particularly insightful, especially when it is meant to ascertain the quality of the legal AI tools relative to a human cohort.
b) Questions cover an unrealistically diverse area of expertise
The other thing to note is that the questions in the study, as far as I can tell, covered at least general contract law, employment law, financial regulation and some level of litigation expertise in dealing with transcripts from a court hearing. For those readers who are not legal professionals: Lawyers who would claim true competence across all of these different practice areas are imposters. Either one of these fields requires years, if not decades, of dedicated exposure and insight, to be truly competent.
Of course one might counter this point by underlining AI's clear advantage in this regard and this is undoubtedly so. My point here is a slightly different one: VLAIR does not make clear how many lawyers from how many of these disciplines they recruited for the human baselining. It would make a huge difference whether they recruited 10 lawyers and asked everyone the entire set of questions, or 50 subject matter experts in the different areas of law were retained.1 It makes a difference, because not knowing this critical detail unnecessarily obfuscates the interpretability of the human baseline results, which, in an attention and headline-grabbing world, 'tickles my spidy sense'.
c) Other open questions
There are a few other questions regarding the human baseline that would benefit from clarification: It would make a difference to the outcome in which way the documents were provided to the lawyers, i.e. was this a virtual data room with downloadable, searchable and printable pdfs or word files, or were the documents essentially images or provided in paper copy? Though the study doesn't get into the potential time-savings beyond some headline figures - which unsurprisingly show that the AI tools are blazing fast in comparison to the human lawyers - it would be useful to know more about how much time lawyers spent on individual tasks and how this was measured.
5. Scoring
Reviewing how the authors designed the scoring of all contributions, i.e. how the results were compiled, left me with two fundamental questions which I would hope to see addressed in the future to improve interpretability of the benchmark:
a) LLM as a judge
VLAIR employed an automated approach to scoring submissions. They used a separate LLM and prompted it to score individual submission. From a cost and efficiency perspective, this is understandable, because it allows to (largely) eliminate human reviewers from the assessment process and for a quicker turn-around. In theory, this standardisation and objectivity also removes 'human drift' from the review process: If you have ever graded papers or exams you will know that one gets increasingly impatient as one progresses through the stack and it's always good advice to revisit the first 15-20% of papers/exams and check for a consistent and fair standard throughout.
However, the reliance on the ‘LLM-as-a-judge’ assessment hinges on either the evaluator LLM's superior ability to assess answers or the study authors’ ability to prompt the model toward that behaviour. Just to be clear, the team behind the benchmark doesn't claim for their evaluator LLM to have superior skills, rather that the
"evaluator model is provided with a reference response to a question, a single element of correctness from the right answer, and guidance on how to evaluate that element. In response, the model returns a verdict of pass or fail with an explanation of its answer."
(1) Potential overfit vs ‘it depends’
I would describe the approach as "few-shot” prompting with a guided evaluation framework and we should be clear about the drawbacks and shortcomings that this method exhibits, which is why I believe reservations about this approach are warranted: A binary pass/fail is quite rigid, and does not account for responses that are mostly correct, but for example slightly incomplete. It also runs the risk 'overfitting' to the single reference-answer, whereas there may be more than one valid way to phrase or interpret an answer. This is particularly an issue, because we have know for over a year, that the premise order has an outsized impact on an LLM’s reasoning ability. Reversing the testing order from the training order (read: prompt) can drop a near perfect performance to almost 0, which is referred to as the ‘Reversal Curse’ of LLMs.2 Moreover, evaluating a single element of correctness at a time by definition means the removal of context, which could well be limiting.
On the contrary, if you have ever dealt with lawyers, you’ll know that their favourite answer is ‘it depends’. Many legal questions cannot easily be reduced to a binary right/wrong outcome because they depend on context, precedent and interpretation. This contrasts with many math or programming benchmarks, where correctness is often (but not always) verifiable in a clear, binary fashion. While some legal AI tasks - such as extracting specific contractual clauses - may be closer to coding or math evaluations, many others, such as analysing the enforceability of a contract clause, are inherently interpretative and as such maybe not (yet) suited for rigid AI evaluation.
The quality of the VLAIR assessment is heavily limited by the fact that the evaluator LLM doesn't have better comprehension of legal reasoning than any of the tools (let along the human lawyers) that partook in the assessment. Ultimately, the 'LLM-as-a-judge' approach is not too dissimilar from selecting a few members of the 1st year law school class to grade the papers everyone has handed in at the end of year 1. For good reason, this is not common practice.
(2) Ensemble methods
One way of addressing these shortcomings would be an ensemble method, where multiple, diverse evaluator LLMs are used to build consensus. Cases where consensus cannot be reached, possibly within a certain margin, would be escalated to a human expert for review. While this might be departure from a general trend where an
"LLM-as-judge methodology is becoming a standard in evaluation for generative AI settings"
I would see it as an acknowledgement of different use-cases in different industries that exhibit different requirements.
(3) Law encodes values
Unlike math or coding, which often allow for purely logical correctness, the 'legal chessboard' is significantly bigger and critically includes other domains. The law operates at the intersection of reason and societal values. It encodes beliefs and norms, which - while influenced by logic - not always and strictly adhered to logic. This reality necessitates evaluation methods that account for ambiguity and subjectivity, which is where an ensemble approach, paired with human oversight, would more accurately reflect how legal reasoning operates in practice.
b) Accuracy percentages and averages as scores
For the scoring mechanism the benchmark employs a percentage pass/fail and for the task of Data Extraction an average with equal weighting of the questions. This is a plausible and straight forward approach, almost the fallback option for this kind of undertaking. However, this simplification somewhat looses track of the use-case - legal AI tools - and thereby potentially distorts the findings.
(1) The authors might want to consider ditching the average as an indicator, because it is not a truly useful in the case at hand. For example, an 80% average accuracy - a supposedly 'decent' score - could be the result of 2 questions, where one came out at 100% and the other at 60%. The problem with using any of these legal tools is: the point of asking the questions is that you need to find out, not because you are on an intellectual quest, already know the answer beforehand and just want to compare notes. Therefore, a solution which might provide a fully correct answer or one, which is closer to 50%, is not actually that useful.
A better, more nuanced display of the tools' capabilities would be box plots, which not only give a total score and/or average, but illustrate the distribution of the results, including outliers (past the min/max points), for a more meaningful assessment:

(2) But there is another, more subtle way in which the benchmark would benefit from revisions: As pointed out earlier already, two of the major unsolved issues with GenAI tools are unreasonably authoritative, though stupidly wrong answers and confabulations. As a consequence, it makes a difference whether a 1,000 word answer is appropriately comprehensive and right, or plainly - or even worse - subtly wrong.
"Instead of trying to be right, try to be less wrong."
- Gurwinder
As a first measure, shorter answers should be preferred over longer, rambling answers. Let me illustrate a point with a drastic example: To answer the question 'which of the clauses in this contract was altered?' by reprinting the entire amended contract is somewhat right and safe, because the amended clause surely is reproduced, but it is also missing the point of the question to a degree that just as much, if not more, signifies failure. Similarly answering a question with a long list of irrelevant observations about the contract and nature of its clauses is not only incorrect, but a waste of the user's time.
Take this example from the benchmark:
A single clause was added to the agreement. The lawyers (easily) found the clause and succinctly described its impact in single paragraph:
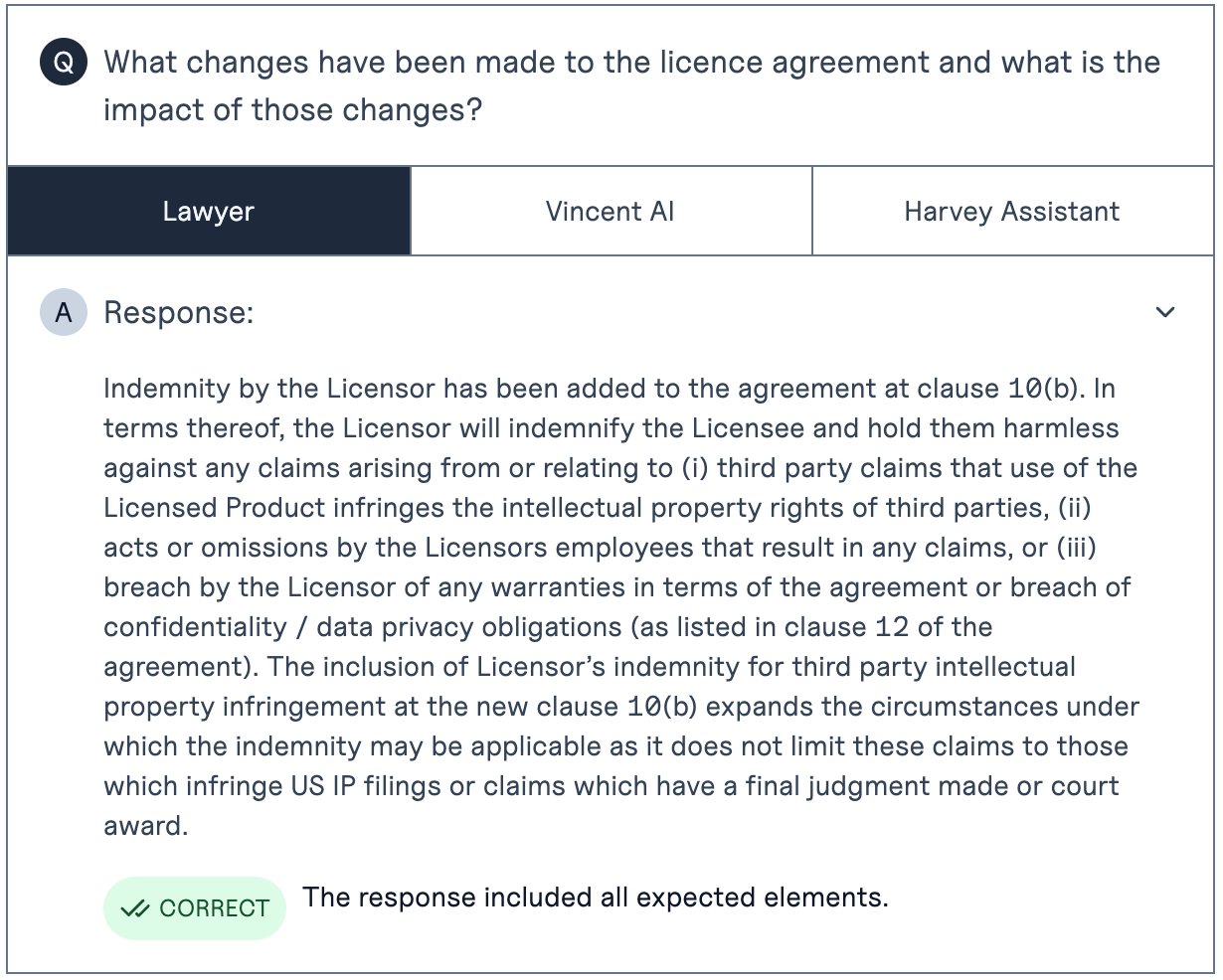
Vincent AI's response was about a page long (ca. 350 words) but didn't answer the question and received a score of 0%:

Harvey Assistant's response was even longer at ca. 660 words, did flag the one clause that actually was changed, but also flagged changes that were not in fact changes (false positives), for a final score of 66%.
Lawyers are often criticised for their 'cover my hind' excessively long and verbose language. Some degree of enforced 'epistemic humility' would improve the quality of the benchmark, where false positives and answers covering irrelevant information or those that are prohibitively long are sanctioned with negative weight in the next iteration of the study. This would introduce a qualitative nuance into the final scores and make the findings more meaningful in my view.
6. Miscellaneous
A disclosure I would have cared to see is simply around financing of the benchmark: Who gave the money to conduct this research? Who donated the compute, the engineering hours etc. Its a useful detail to enhance transparency and identify any potential conflicts of interest that would make the ranking of these commercial products more reliable than forgoing this information altogether.
Though the differences between common and civil law are in my view - certainly from a practical perspective - often overstated, new iterations of the study should explicitly cover the civil law market. Similarly, it would be interesting to see how the tools fare in languages other than English.
D. Conclusion
Despite what you might think, I like to see efforts like VLAIR take shape. Only if AI tools are reviewed without favour and agenda, will potential users as well as providers get a sense of the current level of abilities and can we have meaningful and dispassionate conversations about how to introduce these tools into the workplace, how to best use them and where the biggest benefits of their use can be reaped.
I hope I was able to convince you that there are many straight-forward and simple ways of improving the benchmark that would have allowed VLAIR to fuel precisely this debate, and I wonder why the authors chose not to engage with the tools in this way. With some modifications this goal is certainly achievable in the future, but in my opinion, currently, we are still falling short to draw any robust conclusions.
The report does mention that participating lawyers were given 2 weeks to complete their assigned work. Seeing that the benchmark consists of 250 tasks across 7 categories in total, it doesn’t strike me as plausible to assume that separate subject matter experts were recruited for each of the 7 categories of tasks, but maybe VLAIR can clarify.
Essentially, for knowledge to be reliably extracted, it must be sufficiently augmented (e.g., through paraphrasing, sentence shuffling, translations) during pre-training of the evaluator LLM. Without such augmentation, knowledge may be memorised but is not necessarily extractable, leading to 0% accuracy, regardless of subsequent instruction fine-tuning or prompting. This is a major issue with the VLAIR approach: https://arxiv.org/abs/2309.14316