



When the Student Turns Teacher
About LLMs that critique LLMs

In Homer’s ‘The Odyssey’ Telemachus returns to Ithaca to reunite with his father Odysseus. By this point Telemachus is no longer the passive, uncertain youth he was at the beginning of the epic. While it would be a stretch to compare LLMs to mighty Greek noblemen, a similar transformation is arguably under way in AI: More and more AI publications elevate AI models from passive student to active teacher.
One such – but by far not the only – example of this trend is OpenAI’s introduction of a CriticGPT on 28 June 2024. This model assists trainers during Reinforcement Learning from Human Feedback (RLHF), a technique long used to improve LLMs.
If you have been reading Guaranteed Dissent, you will know that I am not especially concerned that Artificial General Intelligence (AGI) is imminent. Nonetheless, it is worth checking in on current LLM capabilities as summer of 2024. I also want to put this development into context with other, similar research and relate it back to the seeming lack of performance improvement we have seen over the last 12 months.
I. RLHF’s Role in Training LLMs
Before we I get into the OpenAI paper, it might be worth to remind ourselves of the LLM training process, which can be broken down into four key stages:
Pre-training involves initially training the model on a vast corpus of text data sourced from the internet, books, articles and other repositories. During this phase, the model learns the statistical properties of language, such as grammar, context and word associations. Through this unsupervised learning process it learns to predicting the next word in sentences.
Supervised Fine-tuning follows, where the pre-trained model is further trained on labelled examples. This stage uses supervised learning techniques, where essentially a (for now) human has prepared question-and-answer pairs, to improve the model’s outputs on particular tasks by learning from these correct examples.
Reinforcement Learning from Human Feedback (RLHF) follows next. In this phase, human evaluators review the model’s outputs and provide feedback based on quality, relevance and correctness. The model uses this feedback to improve its performance iteratively (i.e. going into a loop repeating this process over and over again), optimising for responses that align better with human expectations.
Finally, Direct Preference Optimisation (DPO) focuses on refining the model by optimising it to align with human preferences. This enhances the model’s ability to produce outputs that are contextually appropriate and aligned with user expectations.
So much for theory. Another, slightly more bleak view of this process is depicted in the popular ‘Shoggoth with Smiley Face’-meme. It symbolises the idea that while AI systems might appear friendly and approachable on the surface, their underlying complexity and potential dangers are hidden beneath this façade and it draws attention to the concerns that human interventions, such as RLHF, are akin to placing a superficial ‘happy mask’ on a fundamentally complex and potentially unmanageable AI system.
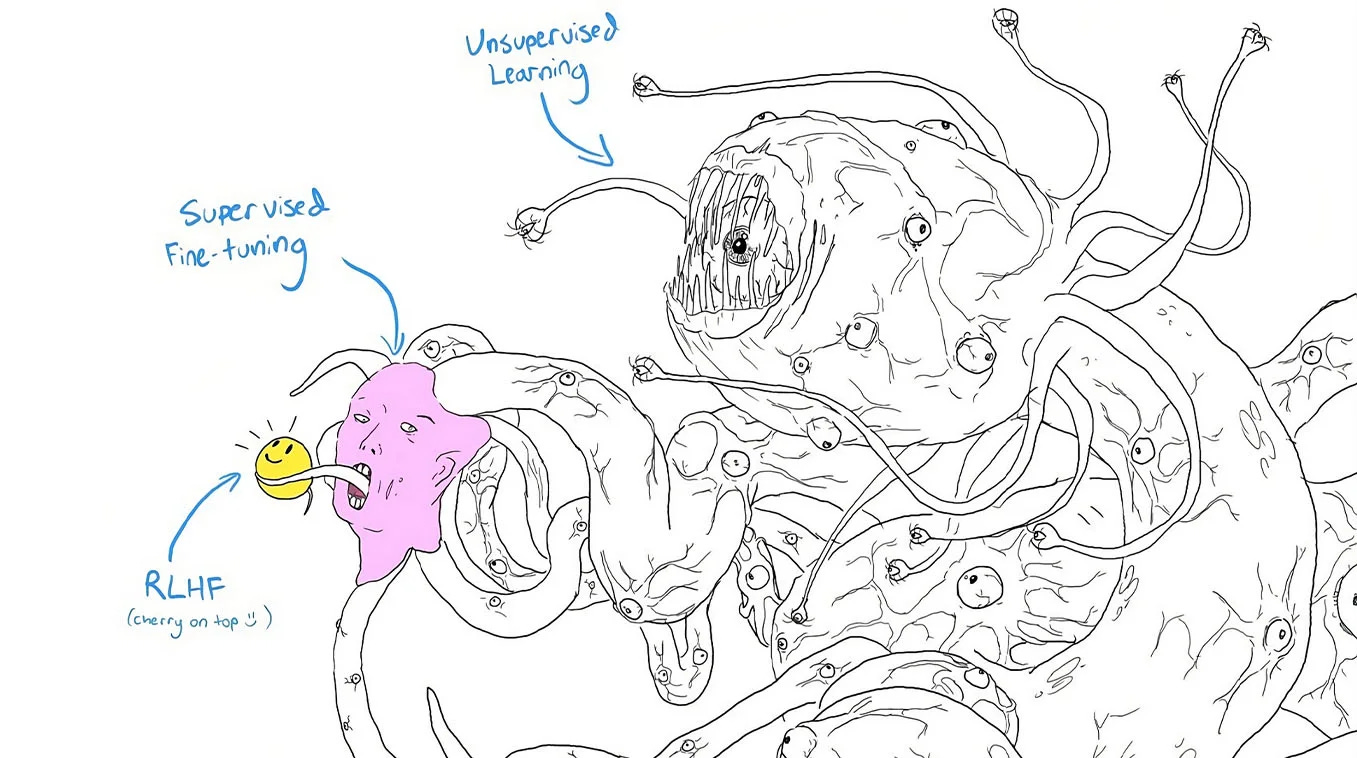
II. LLM to Critique LLM
Human Evaluators’ Limitations
As LLMs continue to advance, the ability of human evaluators to assess their outputs accurately during RLHF has started to diminish. The challenge is twofold: the sheer volume of information, but also the intricate nuances present in sophisticated model outputs. OpenAI’s paper highlights that we are rapidly approaching a threshold where the traditional RLHF approach is no longer sufficient. The fundamental limitation now lies in the human capacity to evaluate and provide meaningful feedback on increasingly complex outputs:
“Large language models have already passed the point at which typical humans can consistently evaluate their output without help. […] The need for scalable oversight, broadly construed as methods that can help humans to correctly evaluate model output, is stronger than ever.”
Introduction of critic models
To address these limitations, the OpenAI introduces ‘critic’ models, i.e. LLMs specifically trained to assist human evaluators by providing natural language feedback on model-written code. These critic models are designed to identify errors in training data more effectively than human evaluators alone and generate detailed critiques of other LLMs’ outputs, focusing on identifying problems and providing corrective feedback.
I want to emphasise that OpenAI’s CriticGPT focuses on writing code and does not have a general use-case across all domains (but also see a neat detail below!).
For context: the Wolfram LLM Benchmarking Project has just shown how critical of an issue this remains today. The best performing model (GPT4), while syntactically near perfect (99.8%), scores a mere 49.7% on functionality.
Nota bene: Just take a moment and reflect on this result! It is worse than a coin toss! If GPT4 didn’t actually attempt to ‘figure it out’, but just flipped a virtual coin, its performance would improve!
In different contexts, other researchers are taking similar approaches, where they rely on LLMs to assist in evaluating LLM reasoning steps for example. One take-away from this observation is that we are beginning to see a much more interwoven, collaborative process where LLMs and humans complete tasks together.
Effectiveness and Transfer Learning
Critiques generated by CriticGPT were preferred in 63% of cases and critic models demonstrated a higher bug detection rate compared to human code review. This underscores the potential of critic models to enhance the evaluation processes of this kind.
I want to draw your attention one more detail: OpenAI also tasked CriticGPT with reviewing ChatGPT training data and it successfully identify hundreds of errors in training data rated as ‘flawless’:
“In 24% of cases contractors indicated that the critique found a problem that substantially decreased the rating of the answer […].”
This is noteworthy, because the majority of those tasks were non-coding tasks and thus ‘out-of-distribution’ for the critic model.
Nota bene: Out-of-distribution in this context means that the data for which the model found ‘flaws’ differed significantly from the type of data the model was trained on and thus not originally designed to handle.
This means that some level of abstraction or ‘transfer learning’ took place during training of the CriticGPT.
Limitations
The researchers also point to several limitations: Code snippets remain short, rather than bugs that could span many lines of code, which makes them more difficult to localise. Also, current use-cases lack multi-file support and repository navigation, which does not reflect the complexity of most software projects. Despite reducing the rates of nits and hallucinated bugs, these issues remain significant.
III. General Lack of Performance Improvement
While I acknowledge that people like ex-OpenAI employee Leopold Aschenbrenner argue that AGI is simply a matter of scale and “strikingly plausible” by 2027, I want to bring the following observation into view, because it is a simple fact: We haven’t seen any groundbreaking performance improvements of LLMs over the last 12 or so months, rather performance of LLMs has been somewhat stagnant, with marginal improvements. As previously mentioned GPT5 is now expected for late 2025, or early 2026. You can also notice convergence of many models on similar performance thresholds. Against the background of the research above this may no longer surprise you. Whether CriticGPTs are about to change all of this? We still have to wait and see, but I doubt significant performance jumps in the near future.
IV. Conclusion and Future Direction
OpenAI’s paper underscores a notable shift in the methodology for evaluating and improving LLMs. On the one hand this shift is nothing short of remarkable, because LLMs’ outputs have already gotten so sophisticated on many occasions, that the only people who could reasonably opine on the output quality are not inclined to spend their time in this way. On the other hand there is still so much that the models struggle with in the strangest ways.
Integrating critic models with traditional RLHF seems like a promising step forward and various researchers are working on similar approaches. All of this is consistent with what some experts have observed for some time now: Smaller, specific models are much more useful and (cost-)effective than their huge counterparts and we could see a lot more of ‘mixture of experts’ approaches in the future.
This seems to lead to one two interpretations:
Version 1 – The people who know best how AI works, are utilising it to achieve better results in their work – maybe you should join them?
Version 2 – The people who know best about AI’s limitations, are running out of ideas and clinging on to the last straw – our dreams are about to be shattered any time now!
Which of these arguments makes more sense to you is likely determined by your personal degree of AI-optimism or -pessimism. In the ‘The Odyssey’ Telemachus supports Odysseus’ goals, working together to reestablish his father’s position without prematurely revealing Odysseus’ disguise as a beggar as they engage Queen Penelope’s suiters. I want to leave you with this optimistic theme of partnership between father and son, teacher and student.