

The Master Without Emissary: General Intelligence
This is Part 1 of a 4-part series on AGI.

Since the release of ChatGPT in Fall 2022 the AI landscape has been dominated by the rapid advancements in LLMs. Many models have been released since. However, despite the general hype surrounding mostly the Transformer technology, they have not lived up to the almost instantaneous promises of how we would soon be approaching Artificial General Intelligence (AGI). Instead, so far they all converge below what seems to be a capability ceiling and we’ve encountered persistent and significant limitations that reveal some fundamental weaknesses of current LLMs.
Inspired by a talk given by François Chollet at the AGI Conference in Seattle just a few days ago I wanted to draw your attention to some of the very good arguments he presents, why we are not in fact anywhere near to breaking through to AGI. This is a very dense and complex topic, so I have opted for a spreading this across a series of posts, rather than one super long post.
A. Issues to Date
The core issue with LLMs is rooted in their autoregressive nature.
Nota bene: Auto-regression refers to the process by which LLMs generate text one word (more accurately: token) at a time, predicting each subsequent word based on the preceding sequence of words. This means the model uses the previously generated words as input and context to predict the next word in the sentence.
Let’s be clear: this allows for truly impressive language generation capabilities, but it also leads to critical shortcomings. One major problem is that LLMs and vision models like Dall-E and Sora tend to produce answers that are statistically likely rather than factually accurate or logically coherent. For text this results in errors when models encounter slightly altered versions of known problems, in images we find unrealistic renderings and typically trouble with depicting language and in videos you regularly witness strange discontinuity of objects or people, that are morphing between frames.
LLMs can appear intelligent when they encounter problems that match templates they’ve seen during training, but they have been known to fail at basic reasoning tasks because they rely on pattern recognition rather than true comprehension. If an LLM encounters a common trick question or logical puzzles like an amended version of the Monty Hall problem, which describes a gameshow scenario and the surprising probabilities in switching one’s choice once the first door is opened. LLMs tend to regurgitate memorized solutions often in bizarre violation of even the most basic reasoning and thereby indicating no genuine understanding the underlying logic. An ever-green is the ‘River Crossing Puzzle’:
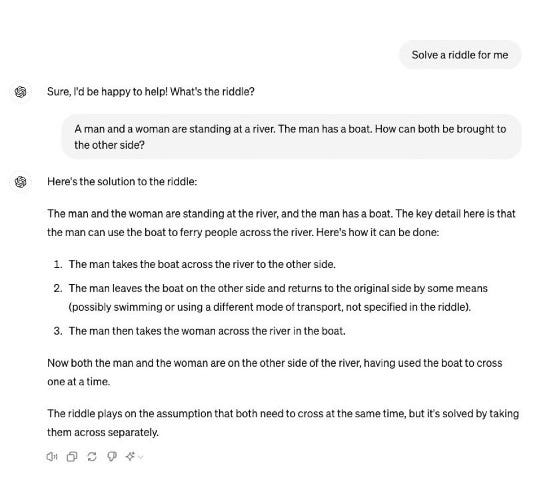
From: Gary Marcus’ X-feed.
Another, similar example, is Caesar’s Cipher, one of the simplest encryption techniques, named after Julius Caesar, who supposedly used it to protect messages of military significance. It’s rather simple: You shift all letters down the alphabet by a given key. Caesar used 3 as the key, so D becomes A, E becomes D, etc.
Confidently solving the problem when using a common key (like 3), LLMs typically fail when the key is changed to a less familiar value. This demonstrates again a lack of true problem-solving capability where these models don’t understand the algorithms they apply; they merely recognize and repeat patterns.
B. Current Solution: Whack-a-Mole of Human Fine-Tuning
To address these issues, the model provides rely heavily on continuous human fine-tuning. When an LLM fails on a specific task, human engineers step in to patch the model by providing it with additional training data and thereby tweaking the model’s parameters. By the way, this is the very reason that typically such examples of failure will be ‘fixed’ after a while. For obvious reasons this approach is not only inherently limited, but also unsustainable. It is not actually a ‘problem solution’ but more akin to patching issues in a ‘whack-a-mole’ approach.

Problems are addressed one at a time, albeit without tackling the root causes. Each time a new variation of a problem arises, the model is fine-tuned. This requires substantial human labour and hence tens of thousands of human contractors working full-time to generate the annotated data needed for model ‘improvement’. Despite these ongoing efforts, the fundamental brittleness of LLMs persists.
The approach also puts tight limits on the oft-heralded scalability of existing models. As and when LLMs are deployed into increasingly complex and diverse environments, the number of edge cases that require human intervention will grow exponentially. This then lets AGI appear further away than bringing it any closer.
C. Defining Intelligence as the Ability to Generalize
The continued quest for AGI raises a crucial question: What is intelligence? Historically, two primary schools of thought have emerged in AI research, represented by two of AI’s founding fathers, Marvin Minsky and John McCarthy.
Marvin Minsky defined intelligence as the ability to perform economically valuable tasks, focusing on task-specific performance. This perspective is prevalent in today’s AI industry as it is in business in general, where success is often measured by how well AI (or a human) performs on a set of predefined tasks.
John McCarthy on the other hand saw intelligence as generalization, or the ability to handle novel problems that one has not been explicitly prepared for. This view emphasizes adaptability and the capacity to solve problems in an unfamiliar terrain, which is closer to what we consider true intelligence in humans.
These nuanced perspectives as stated here evolved over time. Both were close collaborators and are attributed as christening the field of AI at a workshop organized by McCarthy in 1956 at the Dartmouth Summer Research Project on Artificial Intelligence. The proposal was for 10 men to work for 2 months:
“An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.”
Almost 70 years ago the goal was already to investigate ways in which machines could be made to simulate aspects of intelligence. While this essential idea has continued to drive the field forward ever since, a universally agreed definition of intelligence does not exist, but our conceptions of machine intelligence have shifted, bringing neuroscience and cognitive science into the fold. The famous Turing Test, while proclaimed to be passed many times by now, may no longer be the right standard to proclaim victory.

Chollet encapsulates the contrast of the two different perspectives in neat analogy: It’s similar to the difference between having a road network and having a road building company. If you have a road network, you can go from A to B for a very specific set of A's and B's as defined on the map. On the other hand, if you have a road building company you can connect arbitrary A's and B's as your needs evolve. In this sense attributing intelligence to a crystallized behavior in the form of a learned skill is a category error, by confusing the output of the process with the process itself. Intelligence in this approach is the ability to deal with new situations, to build new roads, but it’s not the road itself.
This is also how we currently understand the brain to be reorganizing itself: by forming new neural pathways via neuroplasticity.
a) Intelligence spectrum
A useful concept in framing what intelligence is, is that of a spectrum rather than a binary attribute. This is not meant as a spectrum of IQ-points, but a spectrum that consists of Minsky’s view on the one hand and McCarthey’s view on the other. A continuum from task-specific skills on the one end – which are essentially static programs designed to solve known problems – and a ‘fluid intelligence’ on the other end, which is characterized by the ability to synthesize new solutions on the fly and generalize across different domains.
b) Operational area
This concept refers to the breadth of situations in which an intelligent system can operate effectively. A truly intelligent system should be able to apply its skills in a wide range of contexts, not just those it has been specifically trained for. An example here is the baffling inability of LLMs to perform simple arithmetic. If in fact the models ‘knew’ how to multiply they wouldn’t be almost right, they would just give the correct answer.

The hurdle here is, of course, the approximation of an answer based on a probability distribution of possible answers, not the application (or comprehension) of algebra as a concept.
c) Information efficiency
This last quality is a measure of how efficiently a system can acquire new skills. A highly intelligent system should be able to learn new tasks with (relatively) minimal data, as it would enable the system to adapt quickly to new challenges without requiring extensive retraining. LLMs, of course, sit on the very opposite end of the information efficiency spectrum. This is turn seems to be one of the crucial roadblocks of current approaches to AGI, because we may simply not have the data (and neither the compute nor energy) needed to instil in models the probability distributions representative of all reality.
Nota bene: Arguably, by these standards, humans are not very efficient at learning either: The optical nerve transports about 20MB per second to the visual cortex. A four-year-old would have been awake for roughly 16,000 hours and processed approximately 1 petabyte of visual data alone, i.e. not even considering any of the of the other 4 senses. For comparison, GPT4 is rumoured to have been trained on circa 45GB of data. However, with this ‘training data’, and depending on whether you ask a parent or a random stranger, a 4-year-old arguably doesn’t yet do many interesting things! On the other hand, the brain can operate on a few bananas a day, so computationally this is astoundingly efficient!
d) Generalization as the critical link
What links all three concepts together then, is the ability to generalize efficiently from the familiar to the unfamiliar, to adapt to new situations that are not represented in the training data.
Generalization is the efficiency with which a system operationalizes past information in order to deal with the future. This can be expressed as a conversion ratio of a) information represented by past experience in the given operational area, into b) novel solutions for an unknown space defied by feature uncertainty.
D. Conclusion
I think its worth reminding ourselves what immense progress we have made with LLMs to date. Just think if you took GPT-4o or Claude 3.5 back a few years, people would be nothing short of astonished. At the same time this does not absolve us from a sober stock-take of where on the path to the holy grail of AGI we currently find ourselves. As of Summer 2024 it seems we have not really made progress on the fundamental question of intelligence, at least not based on a broader definition, inspired by human-like abilities.
Parting Note: This is Part 1 of a series of posts around the topic of AGI. Next time I want to compare our current approach to building AI (and systems in general) and how this contrasts with naturally evolving systems. Part 3 will then likely cover ARG-AGI as an attempt to benchmark current progress toward AGI. Part 4 should then conclude with some ideas on what kind of approach could turn out to be useful going forward.