

ARC-AGI - one to rule them all?
On a US$1m prize to make actual progress toward AGI and an intelligence test that you'd score about 10x as well as GPT-4o.

A. Introduction
The surge in capability of AI systems over the last 2 years has garnered a lot of attention by the general public and businesses alike, leading to increased scrutiny on how we measure the capabilities of these AI systems. Benchmarks have emerged as the primary tool for assessing AI performance, but they come with their own set of challenges and limitations. In this part 3, I want to take a look at the current state of AI benchmarks, with a particular focus on the Abstraction and Reasoning Corpus for AGI (ARC-AGI), a benchmark designed to push the boundaries of what we consider general intelligence.
B. Benchmarks
Idea
Just like in every other aspect of life benchmarks in AI are standardised tests used to evaluate the performance of AI systems. They serve as a measure of an AI’s capabilities, and ideally intelligence, providing a way to compare different models and track progress over time. These benchmarks typically consist of tasks from different domains that require some levels of comprehension, problem-solving, possibly reasoning and creativity.
Typical Benchmarks
There is a plethora of widely used benchmarks to evaluate AI systems. It is difficult to select one ‘leading’ benchmark as they all evaluate slightly different aspects of model capability. As you can see from the table below model makers use a subset of benchmarks. Somewhat unsurprisingly, the model makers showcase benchmarks on which their models perform better than their competition and leave out other ones. A rascal is he who thinks ill of it.
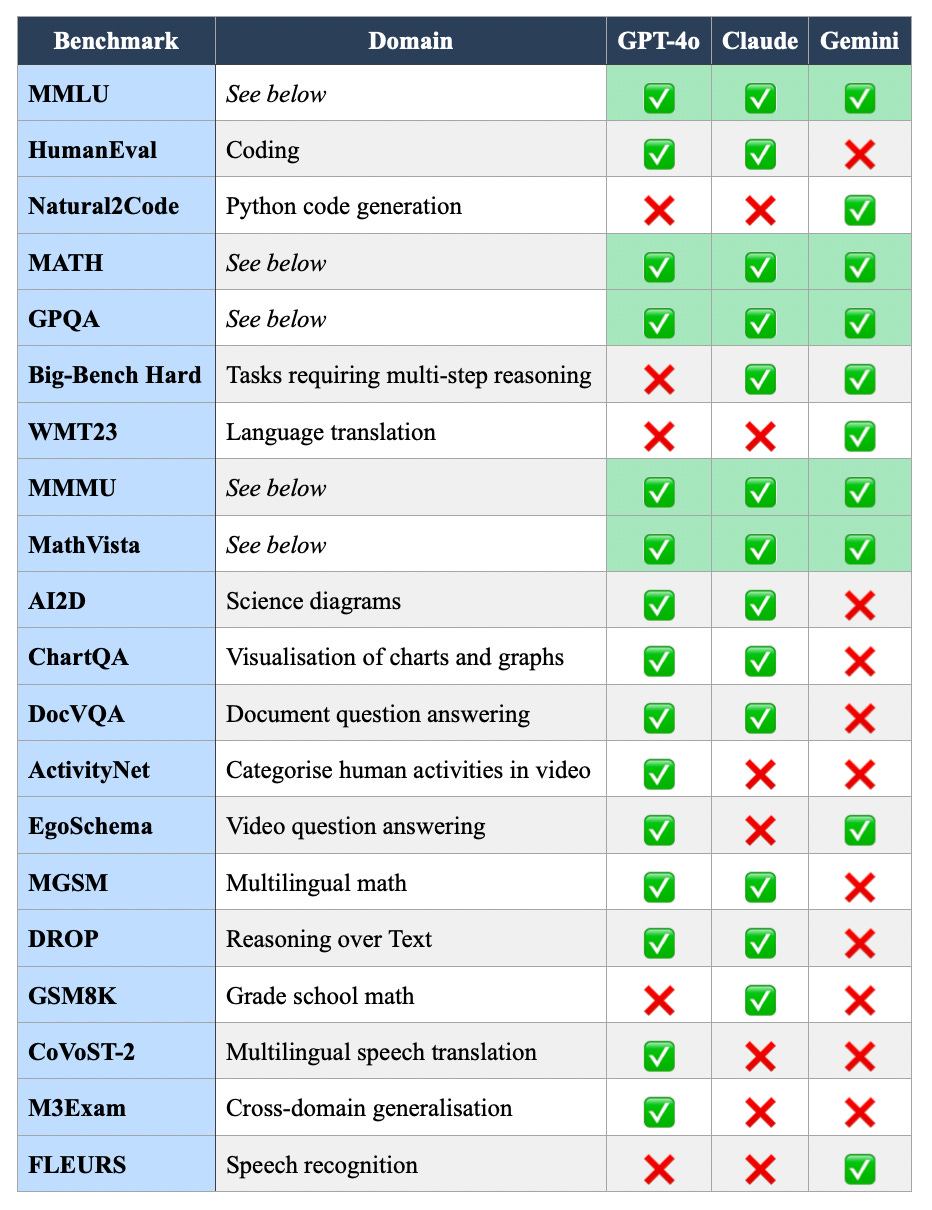
Here is an overview the 5 benchmarks everyone seems to be able to agree on for the moment:
GPQA (General Purpose Question Answering): Assess an LLM’s ability to answer questions that require a broad understanding across topics, including general knowledge, reasoning and more complex inference. It challenges models to not only retrieve information but also synthesise and apply knowledge in a flexible, general-purpose manner.
MMLU (Massive Multitask Language Understanding): Evaluates LLMs across multiple domains, including academic fields like math, history and law, and features over 57 tasks with multiple-choice questions designed to test a wide range of knowledge and reasoning challenges, as an indicator of a model’s versatility and depth of understanding.
MATH: Focused on assessing mathematical reasoning and problem-solving skills. It consists of challenging problems from high school math competitions, covering topics such as algebra, geometry and calculus, to test on understanding and generating correct solutions, highlighting capabilities in quantitative reasoning.
MathVista: Evaluates performance on advanced mathematical reasoning and visualisation tasks, beyond only solving equations, but also interpreting and generating visual representations of math concepts, such as graphs and geometric shapes, to test understanding and manipulation of mathematical visualisations.
MMMU (Multilingual Massive Multitask Understanding): Considers understanding and performance on tasks across multiple languages and includes a wide range of tasks, from translation and cross-lingual information retrieval to language-specific tasks like idiom comprehension, to demonstrate multilingual capabilities and generalise across different linguistic contexts.
There are also places that aggregate this kind of information, do some performance testing of their own and add some additional, more hands-on information as well. A good place to refer to is Artificial Analysis, because they include other useful details such as price and speed. What is interesting here is that their results are not always in line with what the model makers themselves communicate as performance achievements.
If you are less keen on calculated benchmarks and simply want to get an idea on the ‘feel’ you can head to the Chatbot Arena Leaderboard, who are crowdsourcing model quality more generally by letting different models battle over the same tasks side by side (for free). Once the answer is generated the user upvotes the better result to see which model created it.

From: https://lmarena.ai/?leaderboard
There are other dimensions on which you can evaluate an LLM, such as robustness, security, privacy, explainability, etc. This overview at Holistic AI gives you an idea.
Benchmark limitations
The evaluation of AI models through benchmarks has become a cornerstone of how progress in the field is measured. When you look at the performance metrics of common benchmarks and the improvements made over the past few years, it’s evident that models have come a long way. Examples abound where performance jumps from ca. 25% in 2019 – equivalent to random guessing – to +95% today, equivalent of human performance. There is two ways of interpreting this: Either models just get so much better, or the benchmarks are not actually that indicative, because they are measuring the wrong KPIs.
In the quest to the broader goal of achieving AGI this is where the bulk of disconnect seems to be buried, which raises a deeper question: What are we actually measuring with these benchmarks?
A closer look reveals, that most benchmarks are structurally based on memorisation or knowledge retrieval. Models tend to perform well when they encounter scenarios that fit within the distribution of examples they have seen during training, i.e. user inputs that are ‘in-distribution’. On the other hand models struggle quite a bit with data which they have not yet encountered, or which is ‘out-of-distribution’. There are two reasons for this: (a) This is part of the fundamental architecture of LLMs and similar GenAI systems, as their billions of parameters are tuned to essentially memorise vast amounts of training data, but fall short of building comprehensive understanding of that data. (b) Systematic reviews also show, that models are systematically overfitted to perform well on certain benchmarks, which means they have at least partially memorised the benchmark questions.
Memorisation over generalisation is in conflict with the hallmark of true intelligence and creativity: effectively handling ‘out-of-distribution’ scenarios, where the situation is novel and cannot be solved by merely recalling a similar past instance.
In a similar way, measuring LLMs on human exams like the SAT or the Bar exam is fundamentally flawed. These exams were conceived with the limitations of human cognitive abilities in mind. The assumption here is always that test-takers have not previously encountered the specific questions and therefore, one can test for general knowledge to unfamiliar problems. This assumption does not hold for AI models, especially LLMs, which may have memorised vast amounts of information, potentially including the very exam-questions.
One last point: The current dynamics of AI research are somewhat conducive to the proliferation of benchmarks. It’s an accepted way to showing and measuring ‘progress’ and there is often a – understandable – rush to achieve the highest score and publish results that surpass the previous state of the art. This competitive landscape leads to innovative solutions to specific problems, but in doing so at times runs the risk of overemphasising on optimizing for specific benchmarks, rather than focusing on broader, potentially more meaningful advancements in AI capabilities.
C. ARC-AGI
Introduction
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) represents a calculated departure from traditional benchmarks.
Nota bene: There is another benchmark, the ARC – for AI2 Reasoning Challenge, introduced by the Allen Institute for AI in 2018.
Launched by Google AI researcher François Chollet in 2019 as part of a broader initiative to drive progress toward AGI, ARC-AGI is designed to test an AI’s ability to generalise and abstract in ways that are crucial for true intelligence. Unlike other benchmarks that focus on narrow tasks, ARC-AGI challenges models to solve novel problems that they cannot prepare for in advance, making it a far more rigorous test of general intelligence.
The core idea behind ARC-AGI is to create a benchmark that is resistant to memorisation, so to effectively test and measure an AI’s ability to generalise from a few examples onto unseen tasks. ARC-AGI is explicitly designed to compare artificial intelligence with human intelligence. To create a level playing field ARC-AGI explicitly lists core knowledge priors it relies on, because humans, even in childhood, naturally possess them:
Objectness: Objects persist and cannot appear or disappear without reason. Objects can interact or not, depending on the circumstances.
Goal-directedness: Objects can be animate or inanimate. Some objects are ‘agents’, they have intentions and pursue goals.
Numbers and counting: Objects can be counted or sorted by their shape, appearance or movement using basic mathematics like addition, subtraction and comparison.
Geometry and topology: Objects can be shapes like rectangles, triangles and circles which can be mirrored, rotated, translated, deformed, combined, repeated, etc. Differences in distances can be detected.
Information that isn’t part of these priors, for example acquired or cultural knowledge, like language, is not part of the ARC-AGI test.
The tasks
A benchmark to test for AGI might sound daunting, but you’ll be surprised. Each task is a series of input-and-output examples followed by the test with only the input. They look like this (with the task to solve on the very right):


This looks quite straight forward, no? How well do you think you would do? You can head to arcprize.org and try yourself!
3. ARC-AGI Performance
Already looking at the examples, but surely if you went and tried yourself, you’ll find that the puzzles are not that hard by human standards. This is also the Chollet’s finding: already a 5-year-old would score around 50%, individual humans perform comfortably in the +90% range and together achieve easily 100%.
In stark contrast current AI models have struggled to perform well on this benchmark. In the pack of state-of-the-art language models Claude 3.5 leads the pack with 21%, GPT-4o scores 9% and Gemini 8%. These pretty weak results are quite surprising, because multi-modal models like GPT-4o are quite good at efficiently flattening and sequentialising input images for analysis. And, well, they do perform well, except only on images they have seen before, not on the more interesting, unseen samples.
One of the highest performances to date is Ryan Greenblatt’s program synthesis approaches, which involves brute-force searching through possible solutions, to solve up to 42% of tasks. He had GPT-4o generate ca. 8,000 Python implementations per problem and then selecting among these implementations based on correctness of the Python programs on the examples. As you can imagine, the compute and electricity required are enormous, but it’s a notable effort and does demonstrate that with sufficient compute, even simple methods can outperform more sophisticated models on problem solving.
The team from MindsAI around Jack Cole currently scores 46%. There is one boring, and one interesting thing going on here: (a) the score is be based on an LLM that is pre-trained on the typically large data set one would use for pre-training, i.e. millions of ARC-like examples. This is quite different from the human that sees the ARC-AGI test for the first time. (b) What is also utilised in this approach and what seems critical to the performance is test-time fine-tuning: for every new ARC-AGI puzzle the LLM seems to receive real-time fine-tuning based on the problem that it encounters. Details on how this is done have not yet been published – though they will have to be, see below. It’s possible that some kind of imitation learning takes place, based on a limited number of ‘expert’ - aka human – demonstrations. This is very interesting, because it would borrow from robotics and push exactly into the direction of one of the key limitations of current AI systems: If you look back at my comparison between artificial and biological systems, the static nature at the execution stage was one of the key differences and shortcomings in today’s AI systems.

The disparity to date between other benchmarks and ARC-AGI highlights both the limitations of current benchmarks and approaches to AI, particularly when it comes to abstract reasoning and generalisation. The gap between human and machine performance underscores the remaining challenges in our pursuit of AGI.
4. ARC-AGI prize
Chollet, together with Mike Knoop, a co-founder of automation software company Zapier, are funding the ARC Prize, a competition to beat the ARC-AGI benchmark. The prize money is a total of USD1 million and 10 November 2024 is the deadline for submissions. There are different tracks and to win prize money, including the highest score and the best paper that makes a relevant contribution to advancing one of the shortcomings the ARG-AGI benchmark is structured around. A score of +85% would win USD500,000. To advance further AI research, participants are required to publish reproducible code and/or methods into public domain to win any prize money.
D. Limitations
While ARC-AGI represents a significant step forward in measuring AI’s general intelligence, it is not without its limitations. Like other benchmarks, ARC-AGI is not perfect and not immune to memorisation either. A brute-force approach of training a model on hundreds of thousands of ARC-type puzzles could achieve good results. But this would also be no more than the admission that only memorisation can get you there. The defeat that is baked into this admission is clear.
Another limitation of ARC-AGI is its reliance on a narrow set of 4 core knowledge systems. While – as best we know – fundamental to human cognition, they do not encompass the full range of knowledge and skills that humans possess. Language, for one, is not yet part of the challenge.
Another currently imposed limitation is ARC-AGI’s narrow focus on specific cognitive tasks, which can help measure an AI’s ability to abstract and generalise within certain domains, while other, relevant areas of cognition are not yet part of the test: Creativity, emotional understanding and social reasoning, all qualities we probably want to see in an AGI, remain untested for the moment.
E. Conclusion
The ARC-AGI challenge hopefully opens up, or at least directs towards inspecting some new doors in future AI research. As and when it becomes ultimately clear that current approaches come up against their architecture’s inherent limitations (or planetary, especially electricity limitations), it should encourage the exploration of other, new ideas. Neuro-symbolic systems and pathfinder algorithms that search the possible solution space, leaning into creativity by trying out and evaluating previously unencountered directions and integrating it all over reasonably abstract knowledge representations. We should look forward to the publication of solutions and ideas once the challenge closes toward the end of the year.
If you are wondering how the new OpenAI GPT-4o1-preview scores on ARC-AGI: it's on par with Anthropic's Sonnet 3.5 at 21% - https://arcprize.org/blog/openai-o1-results-arc-prize